概述
这个算法算法是我在面临为负载均衡分发时思考的,但没想到已经有人和我想到一块了。
场景是我需要做一个分发任务的项目。一开始我希望实现一个打分排序机制来实现对任务的分发,打分机制需要考虑
- 任务执行端目前能接受的任务数量
- 任务执行端目前正在排队的任务数量
- 任务执行端被投诉的数量(分发到任务端失败或被驳回时会被投诉)
因此一开始是希望一个简单的排序机制,对任务进行轮询分发。但分发任务可能是多进程的,很可能会出现大家一起逮着一个高分使劲薅的情况(因为任务执行端的状态返回有延迟),因此打算使用一种洗牌算法,对执行端进行随机排序。但执行端之间还是有不同的,因此需要按照某种方式,让随机情况尽可能的符合分数从高到低的趋势(随机了,但没有完全随机,排序了,但没有完全排序)。
于是我考虑到了洗牌算法,并想着通过重复计数或者区块划分的方式来实现随机获取。
重复计数洗牌
重复计数洗牌可以参考这篇回答的第一个方法。原理就是根据权重数量,举一个简单的例子:
现在有A,B,C,D四个执行端,他们的权重分别是:
- A: 3
- B: 2
- C: 1
- D: 4
那么,我们可以按照权重数量,生成一个数组:
AAABBCDDDD
接下来,我们可以通过random_shuffle方式,对上面的数组洗牌,变成下面的数组:
DACADBDABD
然后只取该数组中第一次出现的元素,于是就成了:
DACB
于是,我们就可以获得我们想要的结果。
代码实现
代码片段:shuffle.py
这里我使用Python来简单实现,用于原理的展示,因此没有优化大量的拷贝操作,故效率不高。
整体分为两部分,一个是算法的实现,和上面的原理说明一致。一个是测试场景的构建,将1-499的数组随机排序50次,然后取每个数的平均位次。
1 | |
验证结果
我们执行上述代码后,可以得到这样一个折线图,可以看到,权重越高(x轴),排名相对越靠前(y轴)。
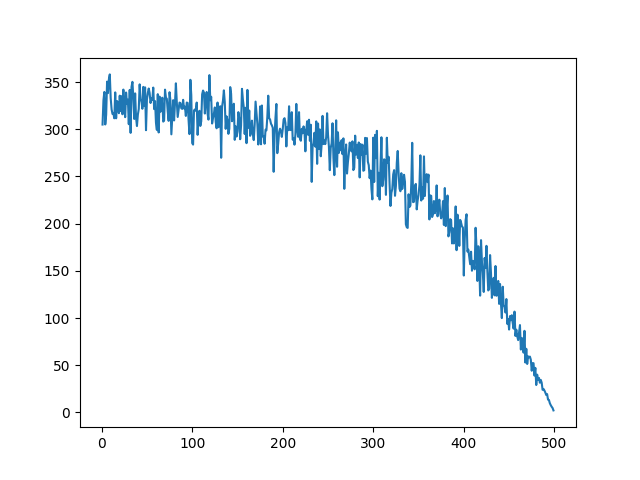
区块划分洗牌
原理与重复计数类似,但实现起来更复杂一点,效率波动比较大,偶尔效率会远超上述算法。
它的原理是根据权重将权重合并成一个划分为好几块的池子,然后我们将一块一块石头随机地丢到池子里,如果池子没有被石头砸过,那就算“命中”,如果被砸过了,那就向两旁看看最近的池子哪个没有被砸,选旁边的一个没有被砸的池子。这个算法的关键在于如何保证快速命中。
为何考虑快速命中,是因为我们的石头是随机丢下去的,我们不清楚他落的范围应该属于谁(水面太大了,不好一点点定位),因此我们需要一些锚点去快速定位,例如丢在了某个旗子(锚点)旁边,那么我们就基于这个锚点来定位石头的未知。
所以我使用了一个快速查找的map,和一个自定义hash方法,来实现锚点,通过hash后,我们可以猜测这个石头在哪个位置,然后左右查看找出符合条件的池子。
代码实现
于是,就成了这样:
1 | |
验证结果
我们执行上述代码后,可以得到这样一个折线图,可以看到,权重越高(x轴),排名相对越靠前(y轴)。
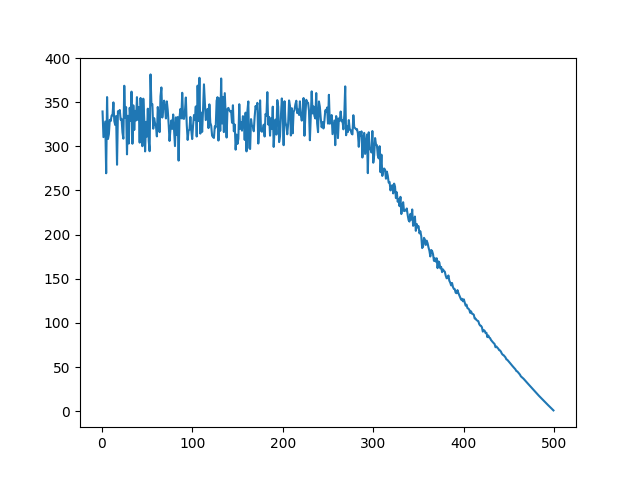
我们观测到,这个并不如重复计数洗牌在低权重上有比较明显的趋势,但如果数量较多的话,也不为一种不错的随机方式。
比较
经过我的大致测试,性能方面,区块划分洗牌性能要较高与重复计数洗牌,500条记录的数组在50次随机时间大致在282618(毫秒, 区块划分洗牌) 和 314019(毫秒,重复计数洗牌)。